
Contents
スプレッドシートのUNIQUE関数とは
スプレッドシートのUNIQUE関数は、特定の範囲内で重複する値を削除して、一意の値のみを抽出する便利な関数です。データのクリーンアップやCOUNTIFとフィルタの組み合わせでも重複削除はできますが、UNIQUE関数は新しく列や表を設けてそのなかで重複を消すため、もとの表をそのままにできるのが強みです。
UNIQUE関数の構文
=UNIQUE(範囲, [行で処理], [重複なし])- 範囲:重複したい列ないし範囲
- 行で処理:行の向きでフィルタしたい場合はTRUE、列の向きでフィルタしたい場合はFALSE
- デフォルトはFALSE
- 重複なし:重複なしの行のみを表示したい場合はTRUE、重複した行を削除したい場合はFALSE
- デフォルトはFALSE
UNIQUE関数の使い方
[基本]1列で重複削除
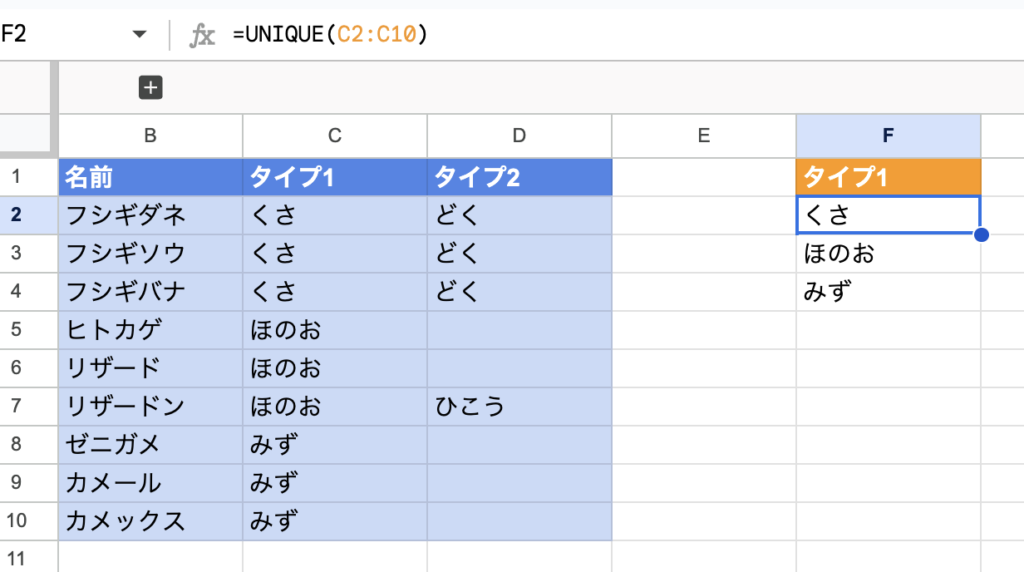
UNIQUE関数の基本的な使い方は、「=UNIQUE(C2:C10)」のように重複削除したい範囲を指定するものです。たとえば下図ではその書き方でC列に書いてあるテキストの重複を削除して、F列に示しています。
[応用1]2列以上で重複削除
UNIQUE関数は2列以上を指定しても重複削除できます。たとえば「=UNIQUE(C2:D10)」とすると、下図のように2列にまたがって重複を削除して表示してくれます。
2列以上に対してUNIQUE関数を使った場合は、すべての列が同じ場合のみ重複としてみなします。たとえば「くさ どく」と「くさ どく」は重複していますが、「ほのお」と「ほのお ひこう」は重複していない扱いです。

[応用2]行で重複削除
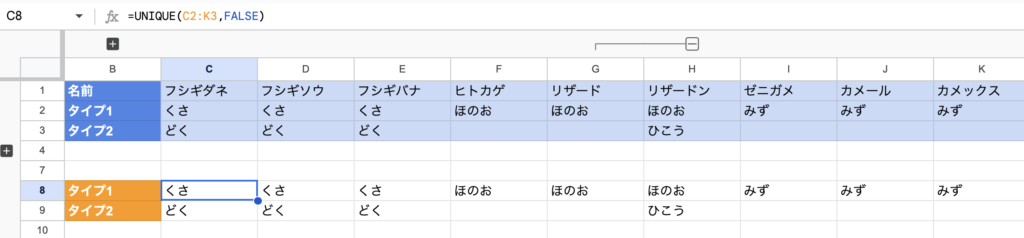
UNIQUE関数は行に対する削除も可能です。「=UNIQUE(C2:K3,TRUE)」のように2つめにTRUEを入れれば、行に対して重複削除を指定できます。

もし仮にFALSEを指定する、なにも指定しない場合には従来通り列に対して重複削除をします。下図では例としてFALSEを入れてみました。
[応用3]重複していない行を削除
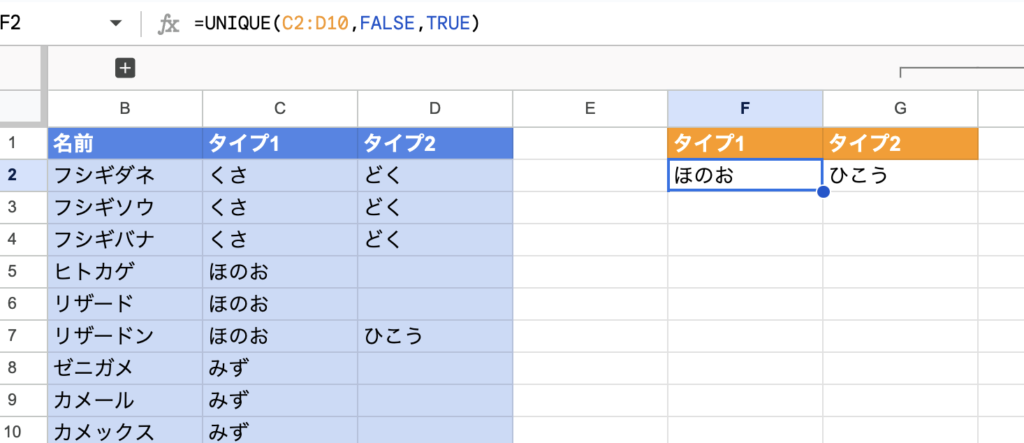
UNIQUE関数はデフォルトでは重複を削除する関数ですが、重複なしの行のみを表示する書き方もできます。下図では「=UNIQUE(C2:D10,FALSE,TRUE)」と書くことで、唯一被っていない「ほのお ひこう」のみが表示されています。
UNIQUE関数に関連する関数
COUNTUNIQUE関数
COUNTUNIQUE関数は、重複していない場合にのみカウントをしてくれる関数です。「=COUNTUNIQUE(B2:B13)」のように記入します。

UNIQUE関数のエラー・注意点
[#REF!]〇〇のデータを上書きするため、配列結果は展開されませんでした。
UNIQUE関数で表示する先に何かしらの値が入っていると「[#REF!]〇〇のデータを上書きするため、配列結果は展開されませんでした。」のようなエラーが表示されます。

これを対処するにはUNIQUEを遮っているセルの値を削除します。





