
Contents
スプレッドシートのIMPORTXML関数とは
IMPORTXML関数は、GoogleスプレッドシートでWebサイト上にあるデータを簡単に取得できる関数です。Web上のデータを収集することをスクレイピングと言いますが、本格的なスクレイピングはプログラミングの技術が必要です。しかし、この関数を使うことで簡単なスクレイピングができます。

スクレイピングはサイトによっては禁止されていることがあるのでサイトの利用規約を確認するのをおすすめします。また、もし禁止されていないとしても連続してのスクレイピングはサーバーに負担をかける原因になるので、常識の範囲内にとどめましょう。
IMPORTXML関数の構文
=IMPORTXML("URL", "XPath")- URL:値を取得したいサイト
- XPath:値を取得したい箇所のXPath
IMPORTXML関数の使い方
IMPORTXML関数を使うには、URLとXPathの指定が必要です。XPathというのはXML Path Languageの略で、平たくいえばWebサイトの構造から要素を特定するのに使える言語です。
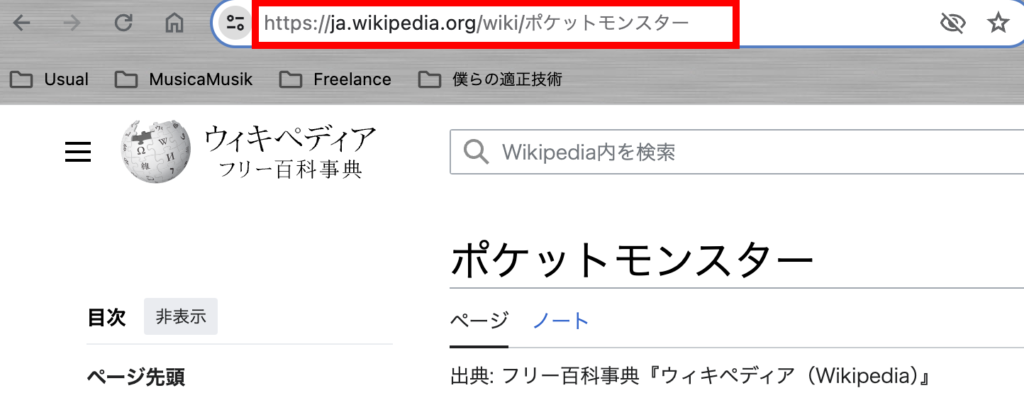
たとえばWIkipediaからタイトルの「ポケットモンスター」の部分を抽出したいとします。

「URL」はブラウザの上部にある箇所からコピーしましょう。
次は「XPath」ですが、ブラウザのデベロッパーツールを使うのがわかりやすいです。ブラウザにもよりますが、Chromeの場合は「…」>「その他のツール」>「デベロッパーツール」の順にクリックしましょう。または「F12」キーを押しても表示できます。

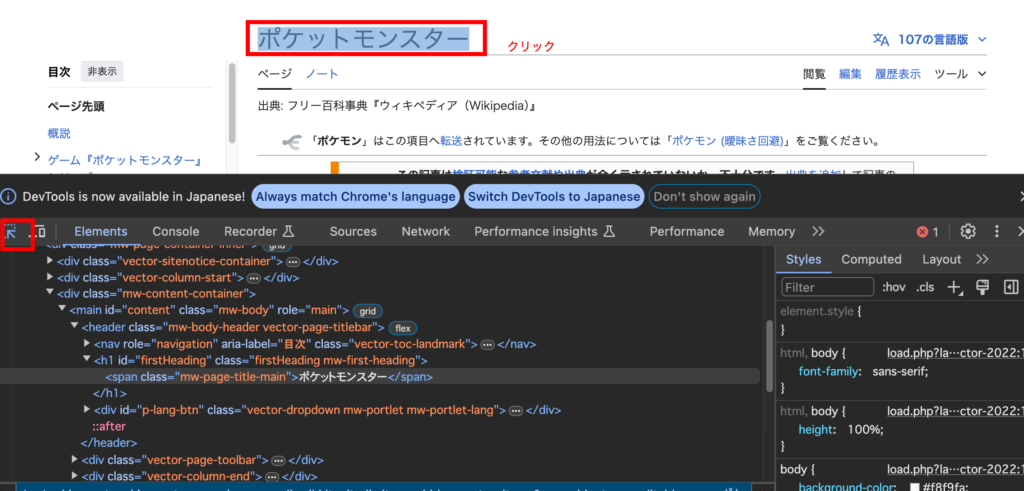
画面半分(右側に出ることもあります)にデベロッパーツールが出てきたら準備完了です。この状態になったら、左側「↖」のアイコンが青色になっているのを確認したうえで、取得したい対象をクリックしましょう。
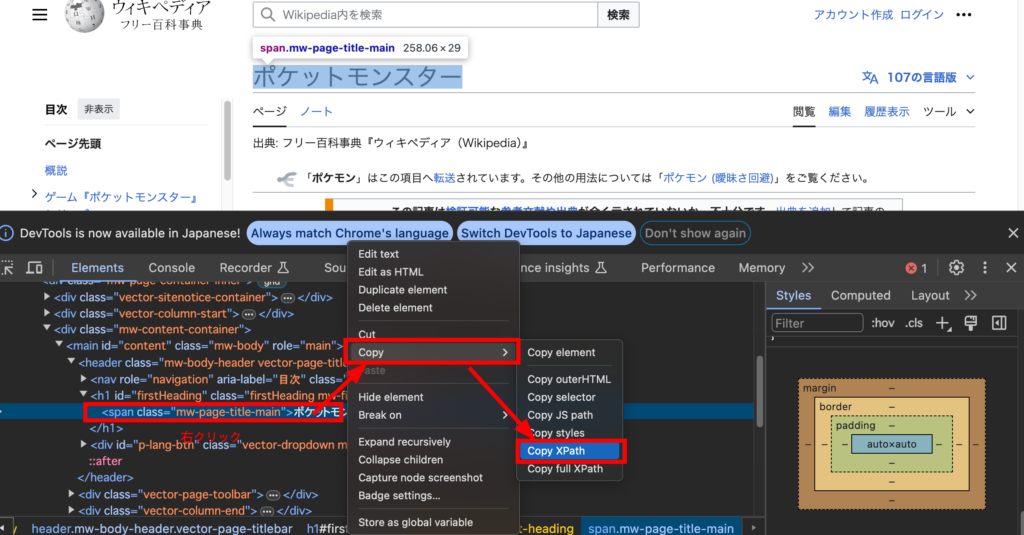
そしたらデベロッパーツール内で該当する部分がハイライトされるので、その箇所を右クリックし、「Copy」>「Copy XPath」をクリックすればコピー完了です!
ではスプレッドシートに戻って、「=IMPORTXML(“URL”, “XPath”)」をスプレッドシートに入力しましょう。はじめてIMPORTXML関数を使う場合は「アクセスを許可」をクリックします。

今回の例では「=IMPORTXML(“https://ja.wikipedia.org/wiki/%E3%83%9D%E3%82%B1%E3%83%83%E3%83%88%E3%83%A2%E3%83%B3%E3%82%B9%E3%82%BF%E3%83%BC”,”//*[@id=’firstHeading’]/span”)」と入力したら、下記のように無事取得できます。

XPathの書き方は実は何通りもあるのですが、はじめてXPathを触れる人が全部理解するのにはやや時間がかかります。そのため、本記事ではデベロッパーツールを使用する方法に解説をとどめます。
もしXPathを詳しく勉強したいのであればQiita / クローラ作成に必須!XPATHの記法まとめがおすすめです。
IMPORTXML関数のエラー・注意点
XPathの「”(ダブルクォーテーション)」は要変換
「//*[@id=”firstHeading”]/span」のようにXPathに「”(ダブルクォーテーション)」が含まれているときは、「'(シングルクォーテーション)」への変換が必要です。たとえば「//*[@id=’firstHeading’]/span」のように変換します。
これをしないと、スプレッドシートの関数に必要なダブルクォーテーションと役割が被ってしまい、意図しない箇所でXPathの指定が終了してしまうので注意しましょう。
サイトの構造が変わると取得できない
IMPORTXML関数はサイトの構造をもとにスクレイピングする都合上、取得元のサイトがリニューアルされるとうまくデータを取れなくなります。サイトの構造まで変更されると意図していた動きをしてくれなくなるので、過信は禁物です。




