
正規表現での置換を調べようとするとJavaScriptやPythonといったプログラミング言語での置換方法ばかりがでてきます。でも非エンジニアにとってそこまでの学習は不要です。本記事では非エンジニアが便利な正規表現の抽出と置換に特化して活用するための方法を解説します。
【準備】正規表現で抽出や置換をするツール
正規表現で抽出や置換をする際には、適したソフトウェアが必要です。テキストエディタが応用しやすく便利なものの、Google ドキュメントやスプレッドシートでも一定の表現は可能なため用途に応じて使い分けてみてください。
テキストエディタ
正規表現の置換をするのに特におすすめなのがテキストエディタと呼ばれるツール群です。その名の通りテキストを編集するためのツールで、特にエンジニアの人が利用するものとなっています。では非エンジニアが使えないのかというとそうではなく、今回紹介するような抽出や置換程度であれば問題なく使えます。
有名なテキストエディタだとたとえば次のようなのがあります。
- Visual Studio Code
- Sublime Text
- さくらエディタ(Windows向け)
- Atom(2022年に開発終了)
非エンジニアの人におすすめするとしたら私はSublime Textを推薦します。有料を促す表示がときおり現れるものの、実質的に無料で使えるので使用頻度が高くないのであれば無料で十分です。
Google ドキュメントやスプレッドシート
もしGoogle ドキュメントやスプレッドシートで置換をしたいのであれば、そのまま使ってもそこまでは問題ありません。
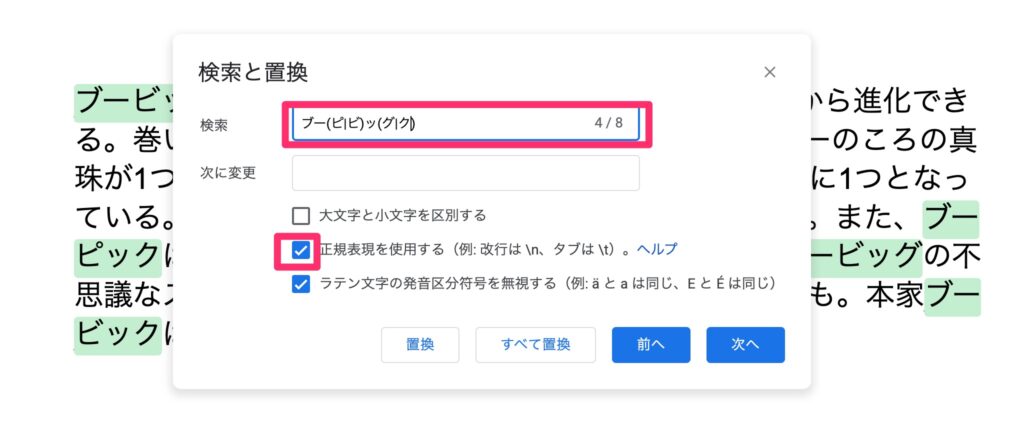
検索と置換の際に「正規表現を使用する」を設定すれば、テキストエディタなしでも利用可能です。ただし使える正規表現が限られているので、詳しくはGoogle ドキュメント エディタヘルプ / 検索と置換にてチェックしてください。
また実際にGoogle ドキュメントで置換をしている様子については次の記事で確認できます。

Wordは注意が必要
マイクロソフトのWordでも正規表現に似たワイルドカードを使えますが、これは正規表現とは異なるので注意が必要です。たとえば「?」が任意の一文字、「*」が任意の一文字以上といった具合です。正規表現のように扱うと混乱しかねません。
詳しくはMicrosoft Office アドイン/ Word アドインの検索オプションを使用してテキストを検索するを覗いてみてください。
正規表現で抽出する方法
正規表現で抽出をする際には大きく2通りの方法があり、1つ目はマッチした文字列全体を抽出する方法、2つ目はマッチした文字列のうち特定の部分のみを抽出する方法です。
パターン1:マッチした文字列の全体
文字列全体を抽出したい場合には、単に正規表現を記載すればOKです。たとえば次の表現では「わざマシン(3桁の数値) (4桁の文字)パンチ」となるように検索をかけています。
// 〇〇〇〇パンチのわざマシンにヒットするように表現
わざマシン\d{3} .{4}パンチ
// 検索の対象
わざマシン067 ほのおのパンチ
わざマシン068 かみなりパンチ
わざマシン069 れいとうパンチ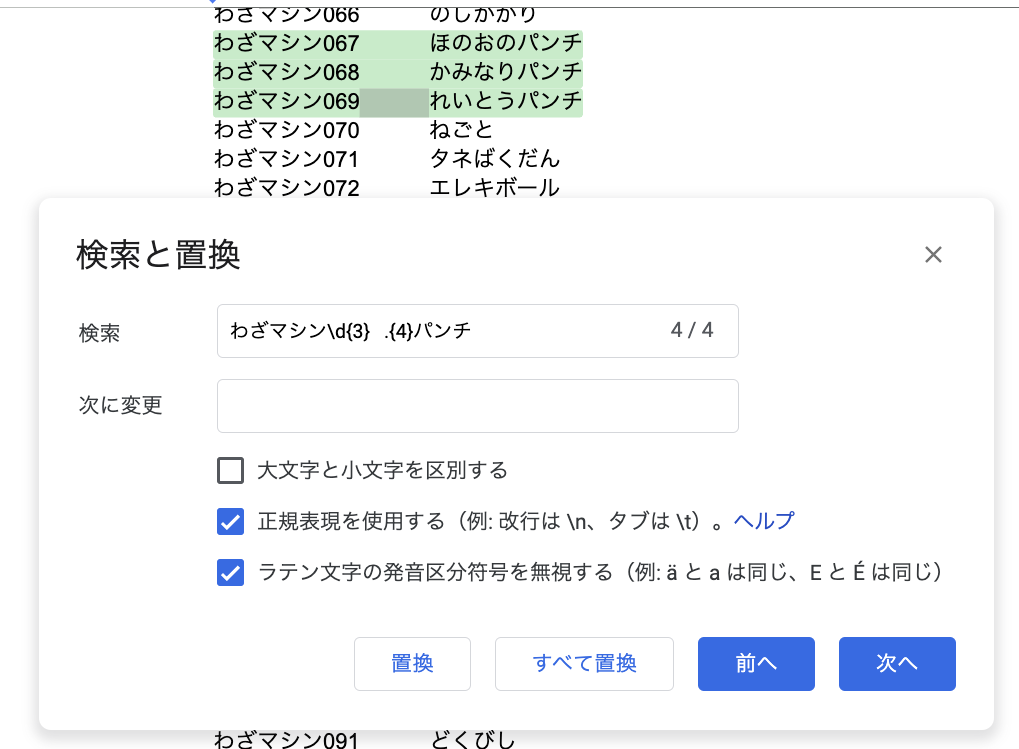
パターン2:マッチした文字列の一部のみ(グループ化)
文字列の一部のみを抽出したい場合には、抽出したい文字列に「( )」をつけましょう。たとえば次の表現では「(4桁の文字)パンチ」を抽出するように検索をかけています。ちなみに「( )」をつけてまとめることをグループ化といいます。
// 〇〇〇〇パンチのわざマシンにヒットするように表現
わざマシン\d{3} (.{4}パンチ)
// 検索の対象
わざマシン067 ほのおのパンチ
わざマシン068 かみなりパンチ
わざマシン069 れいとうパンチ
// 抽出する文字列
ほのおのパンチ
かみなりパンチ
れいとうパンチ
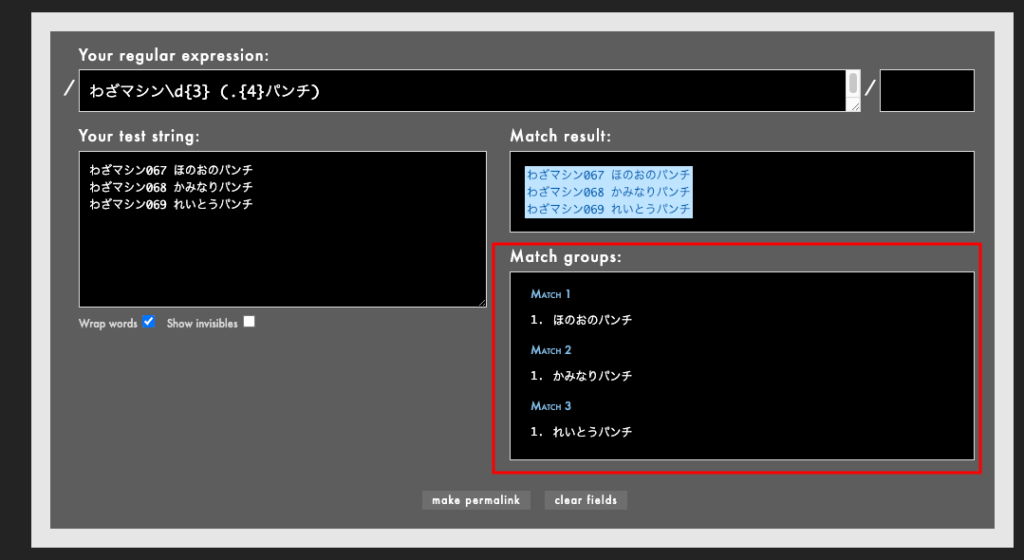
抽出をしただけでは効果を実感しづらいですが、後述の置換する際に役立つのでやり方をおさえておきましょう。

ちなみにスプレッドシートの「REGEXEXTRACT」「REGEXREPLACE」といった関数を使う場合には「( )」でくくることで( )内の文字を対象とした抽出や置換が可能です!
グループを抽出させない回避方法
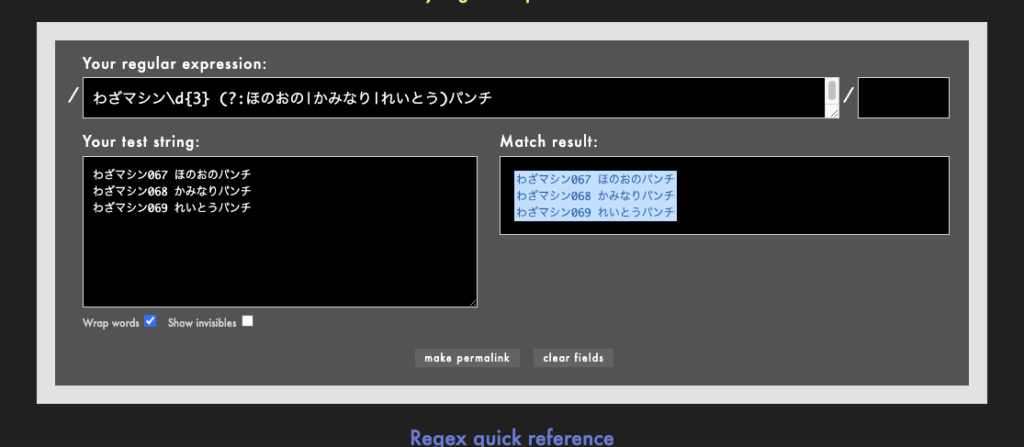
正規表現にてキャプチャ以外の目的で「( )」を使う際には「(?: )」とすることでキャプチャされるのを防げます。
グループ化は抽出以外にも「(ポケモン|Pokemon)」のようにどちらかを選択するようにまとめたり、「(ピカチュウ)+」のように()内の文字列全体を繰り返すように表記したりもできます。ただ、この場合であっても抽出はされてしまうため「(?: )」による対策が必要です。
// 〇〇〇〇パンチのわざマシンにヒットするように表現
わざマシン\d{3} (ほのおの|かみなり|れいとう)パンチ
// 検索の対象
わざマシン067 ほのおのパンチ
わざマシン068 かみなりパンチ
わざマシン069 れいとうパンチ
// 抽出する文字列
ほのおのパンチ
かみなりパンチ
れいとうパンチ上記では「(ほのおの|かみなり|れいとう)」とすることでどれか1つに当てはまれば◯としたいのですが、意図しないキャプチャがなされています。
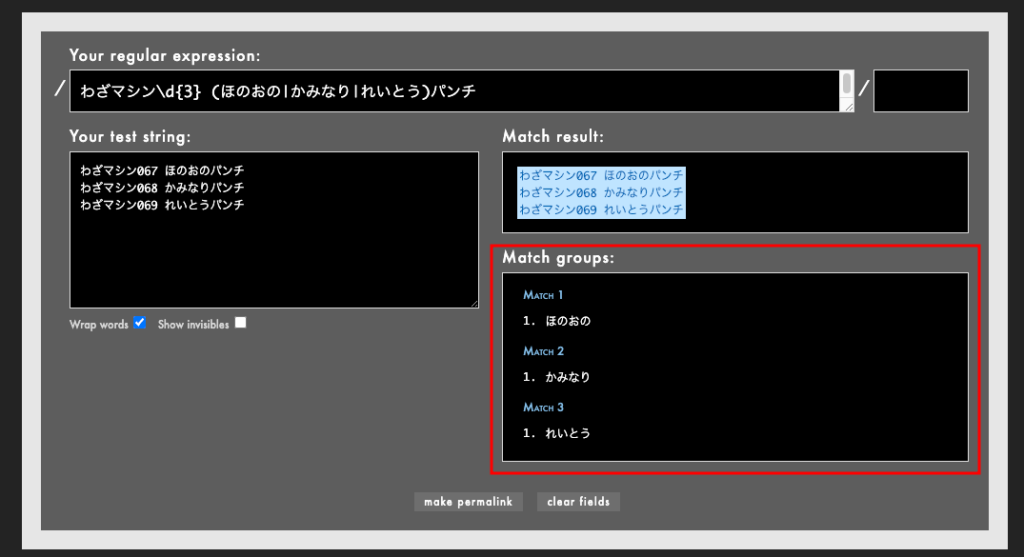
これを防ぐには「(?:ほのおの|かみなり|れいとう)」とします。
正規表現で置換・変換する方法
正規表現で置換ないし変換をする場合には、マッチした文字列を上書きする形で変換するパターンとマッチした文字の一部を利用して変換するパターンの2つがあります。
パターン1:マッチした文字列に関係なく置換
マッチした文字列に関係なく置換するパターンにおいては、置換先の文言をひとつに決めてそれへ置き換える方法をとります。正規表現を用いない置換をした際の挙動とさほど遠くない形です。
// 検索する文字列
わざマシン\d{3} .{4}パンチ
// 置換する文字列
ひでんマシン01 いあいぎり
// 置換前のの文字列
わざマシン067 ほのおのパンチ
わざマシン068 かみなりパンチ
わざマシン069 れいとうパンチ
// 置換後の文字列
ひでんマシン01 いあいぎり
ひでんマシン01 いあいぎり
ひでんマシン01 いあいぎり検索してマッチした3行の文字列それぞれを「ひでんマシン01 いあいぎり」へと変更しています。
パターン2:マッチした文字列の一部を残して置換
マッチした文字列の一部を残して置換する際には、「( )」の中身を「$1」として置き換えることで実現できます。検索時に「(ピカチュウ)」となっていたら置換時には「$1」とかくことで結果に「ピカチュウ」を残せます。
// 検索する文字列
わざマシン\d{3} (.{4}パンチ)
// 置換する文字列
エビワラー Lv.24 $1
// 置換前の文字列
わざマシン066 のしかかり
わざマシン067 ほのおのパンチ
わざマシン068 かみなりパンチ
わざマシン069 れいとうパンチ
わざマシン070 ねごと
// 置換後の文字列
わざマシン066 のしかかり
エビワラー Lv.24 ほのおのパンチ
エビワラー Lv.24 かみなりパンチ
エビワラー Lv.24 れいとうパンチ
わざマシン070 ねごと上記の例は次のような流れで置換が行われています。
- 「わざマシン\d{3} (.{4}パンチ)」にマッチする文字列を探す
- マッチした文字列の「(.{4}パンチ)」を抽出しておく
- 「エビワラー Lv.24」に続く形で抽出しておいた「(.{4}パンチ)」を表示
その結果「(.{4}パンチ)」が「ほのおのパンチ」「かみなりパンチ」「れいとうパンチ」へと受け継がれつつその他の箇所は違う文字へ置換されています。
なおグループ化「( )」を複数していればその数に応じて「$2」「$3」へと展開していきます。
// 検索する文字列
(.+)博士:(.+)
// 置換する文字列
$1博士は$2地方にいます
// 置換前の文字列
オーキド博士:カントー
ウツギ博士:ジョウト
オダマキ博士:ホウエン
ナナカマド博士:シンオウ
// 置換後の文字列
オーキド博士はカントー地方にいます
ウツギ博士はジョウト地方にいます
オダマキ博士はホウエン地方にいます
ナナカマド博士はシンオウ地方にいます上記では博士の名前と地方をキャプチャしておき、置換後の文字列で使用しています。1つ目の「(.+)」は「$1」、2つ目の「(.+)」は「$2」にて置換後の文字で利用しているのが上の例です。
正規表現を用いた置換の強みはグループ化した文字列を利用できる点にあるので、ぜひ活用していきましょう。




